
Эта статья является продолжением знакомства с возможностями библиотеки Apache POI. В прошлой статье мы научились создавать новые Word документы на Java, а сегодня рассмотрим простой пример считывания данных с файлов в формате docx.
Считывание Word документа с помощью Apache POI
Давайте рассмотрим краткие теоретические сведения по работе с библиотекой, колонтитулами и параграфами. Считанный в память docx документ представляет собой экземпляр класса XWPFDocument, который мы будем разбирать на составляющие. Для этого нам понадобятся специальные классы:
- Отдельные классы
XWPFHeaderиXWPFFooter— для работы (считывания/создания) верхнего и нижнего колонтитулов. Доступ к ним можно получить через специальный класс-поставщикXWPFHeaderFooterPolicy. - Класс
XWPFParagraph— для работы с параграфами. - Класс
XWPFWordExtractor— для парсинга содержимого всей страницы docx документа
Apache POI содержит множество других полезных классов для работы с таблицами и медиа объектами внутри Word документа, но в этой ознакомительной статье мы ограничимся лишь с разбором колонтитулов и парсингом текстовой информации.
Пример чтения документа Word в формате docx с помощью Apache POI
Теперь добавим в проект библиотеку Apache POI для работы с Word именно в docx формате. Я использую maven, поэтому просто добавлю в проект еще одну зависимость
|
1 2 3 4 5 |
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.11</version> </dependency> |
Если вы используете gradle или хотите вручную добавить библиотеку в проект, то найти ее можно здесь.
Парсить/считывать я буду docx документ, полученный в предыдущей статье — Создание Word файла. Вы можете использовать свой файл. Содержимое моего документа следующее:
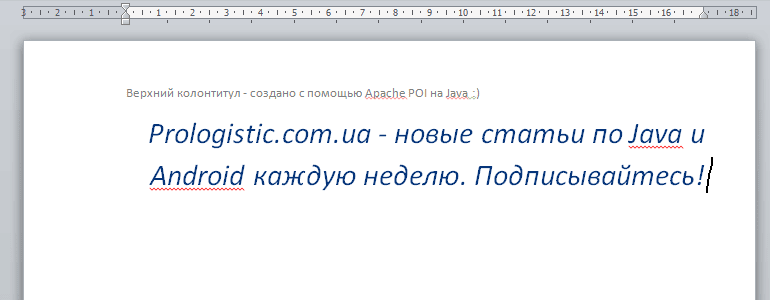
Теперь напишем простой класс для считывания данных из колонтитулов и параграфов документа:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
package ua.com.prologistic.excel; import org.apache.poi.openxml4j.opc.OPCPackage; import org.apache.poi.xwpf.model.XWPFHeaderFooterPolicy; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.apache.poi.xwpf.usermodel.XWPFFooter; import org.apache.poi.xwpf.usermodel.XWPFHeader; import org.apache.poi.xwpf.usermodel.XWPFParagraph; import java.io.FileInputStream; import java.util.List; public class WordReader { public static void main(String[] args) { try (FileInputStream fileInputStream = new FileInputStream("F:/Apache POI Word Test.docx")) { // открываем файл и считываем его содержимое в объект XWPFDocument XWPFDocument docxFile = new XWPFDocument(OPCPackage.open(fileInputStream)); XWPFHeaderFooterPolicy headerFooterPolicy = new XWPFHeaderFooterPolicy(docxFile); // считываем верхний колонтитул (херед документа) XWPFHeader docHeader = headerFooterPolicy.getDefaultHeader(); System.out.println(docHeader.getText()); // печатаем содержимое всех параграфов документа в консоль List<XWPFParagraph> paragraphs = docxFile.getParagraphs(); for (XWPFParagraph p : paragraphs) { System.out.println(p.getText()); } // считываем нижний колонтитул (футер документа) XWPFFooter docFooter = headerFooterPolicy.getDefaultFooter(); System.out.println(docFooter.getText()); /*System.out.println("_____________________________________"); // печатаем все содержимое Word файла XWPFWordExtractor extractor = new XWPFWordExtractor(docxFile); System.out.println(extractor.getText());*/ } catch (Exception ex) { ex.printStackTrace(); } } } |
Запустим и смотрим в консоль:
|
1 2 3 4 |
Верхний колонтитул - создано с помощью Apache POI на Java :) Prologistic.com.ua - новые статьи по Java и Android каждую неделю. Подписывайтесь! Просто нижний колонтитул |
Начинающие Java программисты, обратите внимание, что мы использовали конструкцию try-with-resources — особенность Java 7. Подробнее читайте в специальном разделе Особенности Java 7.
Другой способ считать содержимое Word файла
Приведенный выше пример сначала парсит отдельные части документа, а потом печатает в консоль их содержимое. А как быть, если мы просто хотим посмотреть все содержимое файла сразу? Для этого в Apache POI есть специальный класс XWPFWordExtractor, с помощью которого мы в 2 строчки сделаем то, что нам нужно.
Просто раскомментируйте код в листинге выше и еще раз запустите проект. В консоле просто продублируется вывод на экран.
Подробнее о библиотеке Apache POI читайте здесь, а также посмотрите пример чтения Excel файла, а также создания Excel (xls) документа все помощью Apache POI.
Подписывайтесь на новые статьи по Java и Android.




Хорошая статья.
Нет ли статьи как считывать данные с таблицы в MS Word (docx).